Transformer
概述
- sequence to sequence任务,目前主要依靠循环或卷积神经网络
- 通过encoder和decoder,和纯注意力完成翻译任务multi-headed attention
- 传统RNN无法并行,需要逐步计算每一步时序信息
- 使用卷积神经网络替换RNN,可以并行,但是无法处理长序列问题,需要设计多层卷积才可以融合长序列。卷积优势是可以构造多通道的输出,从而可以识别不同的模式
- 通过注意力机制,每一层可以融合所有的时序信息
- 设计多头注意力层,实现卷积网络识别不同模式
模型
- encoder: 输入$(x_{1}, x_{2}, …, x_{n})$编码器输出$(y_{1}, …, y_{n})$,类似embedding
- decoder: 获得编码器的结果,生成长度为$m$的序列$(y_{1}, …, y_{m})$,并且解码器中$y_{i}$是依次输出的(自回归)
![]()
encoder:包含6个相同的编码层,- 每层包含
multi-head self-attention与simple, position-wise fully connected feed-forward network两个子模块(后面层实际上是一个MLP) - 各层之间存在残差连接
layer normalization: 对于batch normalization的缺点,在训练时,对BN来说需要保存每个step的统计信息(均值和方差)。在测试时,由于变长句子的特性,测试集可能出现比训练集更长的句子,所以对于后面位置的step,是没有训练的统计量使用的。不同句子的长度不一样,对所有的样本统计均值是无意义的。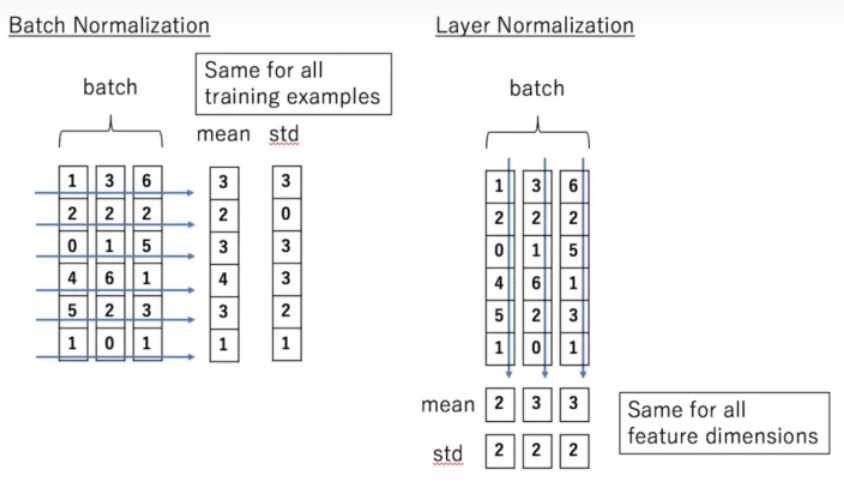
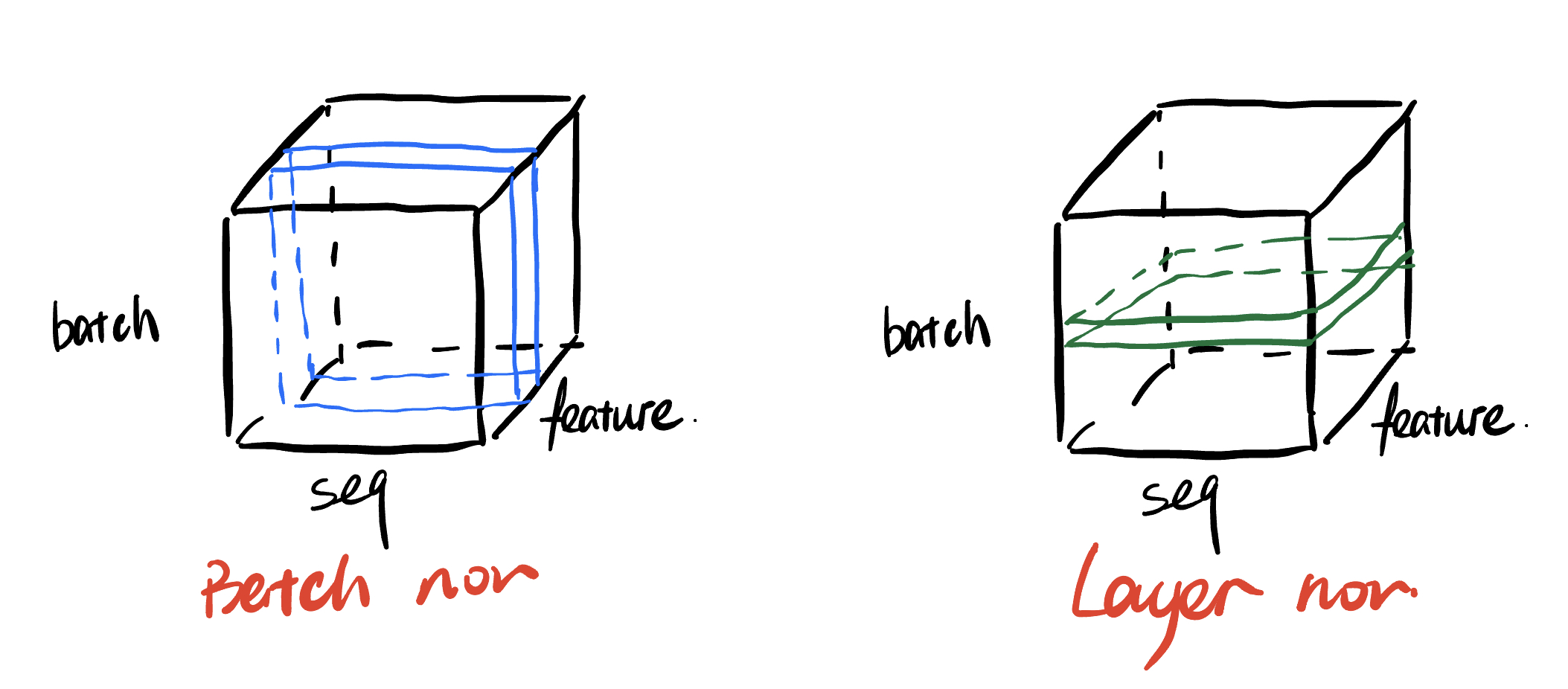
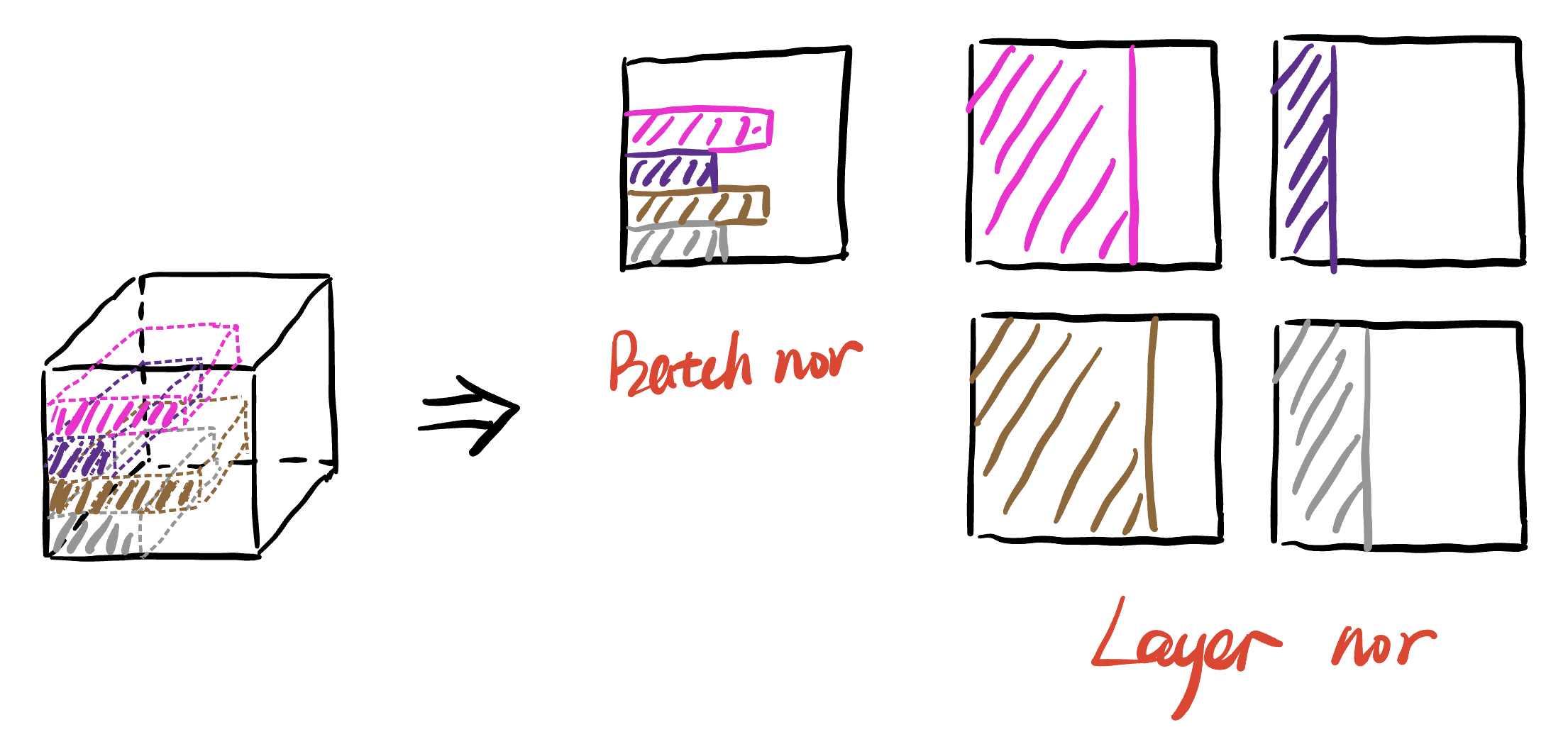
- 每层包含
decoder:Masked Multi-Head Attention: 保证$t$时刻只能看到之前的数据,即进行自注意力的时候,只进行$k_{1},…,k_{t-1}$的运算(计算输出的时候将$k_{t}$后面的所有数变成一个无穷小负数)Multi-Head Attention: 首先通过linear进行降维(具有可学习参数),进行h次注意力解码器中第二个注意力模块非自注意力,
key,value来自最后一个编码器的输出,q来自解码器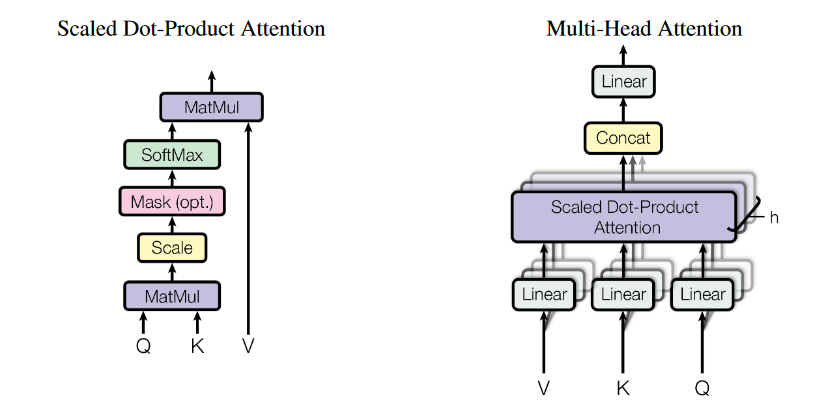
Position-wise Feed-Forward Networks: 本质上是一个MLP,对输入的每一个词作用同样的一个mlp- $FFN(x) = max(0, xW_{1}+b_{1})W_{2} + b{2}$
- 作用:语义信息的转换,attention层进行语义信息汇聚
Embedding: 单词,映射为,向量position encoding:- Attention 没有时序信息
- 在输入中添加时序信息,使用sin与cos周期函数